High Performance, Low Power Matrix Multiply Design on ACAP: from Architecture, Design Challenges and DSE Perspectives
Abstract
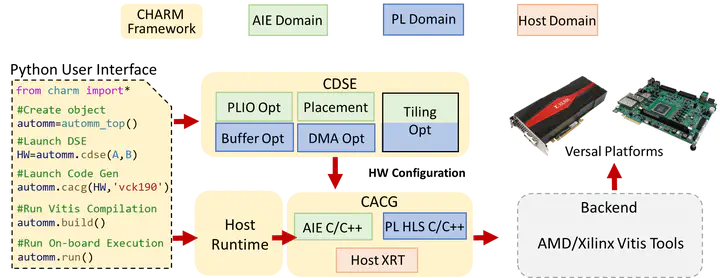
As the increasing complexity of Neural Network(NN) models leads to high demands for computation, AMD introduces a heterogeneous programmable system-on-chip (SoC), i.e., Versal ACAP architectures featured with programmable logic(PL), CPUs, and dedicated AI engines (AIE) ASICs which has a theoretical throughput up to 6.4 TFLOPs for FP32, 25.6 TOPs for INT16 and 102.4 TOPs for INT8. However, the higher level of complexity makes it non-trivial to achieve the theoretical performance even for well-studied applications like matrix-matrix multiply. In this paper, we provide AutoMM, an automatic white-box framework that can systematically generate the design for MM accelerators on Versal which achieves 3.7 TFLOPs, 7.5 TOPs, and 28.2 TOPs for FP32, INT16, and INT8 data type respectively. Our designs are tested on board and achieve gains of 7.20x (FP32), 3.26x (INT16), 6.23x (INT8) energy efficiency than AMD U250, 2.32x (FP32) than Nvidia Jetson TX2, 1.06x (FP32), 1.70x (INT8) than Nvidia A100.
Jinming Zhuang
Ph.D. Student
My research interest lies in heterogeneous computing with FPGAs, GPUs, ASICs and NPUs, compiler design and programming abstraction, and hardware & software co-design.